
Dans un article précédent, j’expliquais comment Spring Cloud Function pouvait faciliter la mise en place d’une architecture Event Driven. Dans le cadre d’un déploiement AWS, la création d’une fonction Lambda est une alternative possible.
Cet article a pour but de décrire la mise en œuvre et le déploiement d’une fonction Lambda à l’aide de Spring Cloud Function et d’en répertorier les principaux écueils.
Application
Description
La fonction prise en exemple est chargée d’extraire d’un document textuel un ensemble de mots clés. Ce document nous est transmis sous forme de DocumentMessage encapsulant la référence du document, son contenu et la liste des mots clés attendus. Un ExtractedKeywordsMessage contenant la référence et la la liste des mots clés extraits est renvoyé par la fonction.
Fonction principale
@Bean Function<DocumentMessage, ExtractedKeywordsMessage> extract() { return extractorService::extract; }
Son implémentation Reactive reste possible :
@Bean Function<Flux<DocumentMessage>, Flux<ExtractedKeywordsMessage>> extract() { return flux -> flux.map(extractorService::extract); }
Optimisation
L’exécution d’une fonction Lambda se fait en deux étapes (voir à ce sujet cet article d’Octo):
-
Cold start : téléchargement du code, démarrage du conteneur, lancement et amorçage de l’application
-
Warm call : temps proprement dit d’éxecution du code
Dans le cadre de Spring Cloud Function, le Cold Start intervient pour une grande part sur le temps d’éxecution total. Afin de le minimiser, il y a tout intérêt à supprimer dans notre code toutes les dépendances non nécessaires. Supprimons par exemple toute référence à Lombok (sous Intellij, grâce à la fonction Delombok du plugin homonyme).
Il peut être utile dans un premier temps d’intégrer un serveur web afin de tester sa fonction. C’est le rôle de l’artifact spring-cloud-starter-function-web. Cette dépendance ne se justifie plus dans le cadre d’un déploiement AWS mais doit être remplacée par contre par le starter spring-cloud-function-adapter-aws. Cela inclut entre autres les librairies spring-web, jackson et reactor.
Cela nous conduit à ne garder dans le pom initial que les éléments suivants :
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-function-context</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-function-adapter-aws</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
Dans application.properties, toute référence au streaming de message n’est désormais plus nécessaire. Supprimons toutes les lignes débutant par spring.cloud.stream.
Packaging
Pour qu’il puisse être déployé dans AWS, le JAR résultant doit comporter non seulement les classes de l’application proprement dite mais aussi celles de toutes les librairies associées. Le plugin Maven shade nous permet de construire ce « Fat JAR » (appelé aussi « Uber JAR ») en n’omettant pas de préciser dans sa configuration des points essentiels comme la classe principale de l’application (Main-Class) ou les transformers liés à l’utilisation de Spring.
L’objectif de ce plugin est de réunir dans un seul jar toutes les dépendances d’un projet en proposant un certain nombre de transformers chargés de résoudre les éventuels conflits ou d’agréger dans un fichier unique les propriétés ou les ressources provenant des librairies incluses. L’AppendingTransformer aura pour rôle par exemple d’agréger dans un seul fichier les informations contenues dans le fichier META-INF/spring.handlers, pouvant être présent à plusieurs endroits.
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <version>2.3.3.RELEASE</version> </dependency> </dependencies> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <shadedArtifactAttached>true</shadedArtifactAttached> <shadedClassifierName>aws</shadedClassifierName> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.handlers</resource> </transformer> <transformer implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer"> <resource>META-INF/spring.factories</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.schemas</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <manifestEntries> <Main-Class>com.adventium.keywords.extractor.KeywordsExtractorFunctionApplication</Main-Class> </manifestEntries> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.ApacheNoticeResourceTransformer"> <addHeader>false</addHeader> </transformer> </transformers> </configuration> </plugin>
Ce plugin est exécuté par défaut dans la phase package du cycle de vie de Maven. La simple commande mvn package permet de générer le jar de déploiement. Après exécution, le dossier de destination (target) comporte deux JARs :
-
un « Thin JAR » ne comportant que les classes applicatives
-
un Fat JAR, réunissant toutes les classes de l’application, librairies incluses
Ce dernier est suffixé paraws, comme précisé dans la configuration sous la mentionshadedClassifierName. C’est ce JAR-là qu’il faut déployer.
Création de la Lambda dans AWS
Commençons par nous familiariser avec la console AWS. C’est le moyen le plus simple pour débuter. Nous verrons par la suite comment effectuer les mêmes opérations au moyen de l’interface en ligne de commande d’Amazon (AWS CLI).
Rendez-vous sur la page dédiée aux Lambdas :
https://xx-xxxx-x.console.aws.amazon.com/lambda/home
xx-xxxx-x correspond à votre région par défaut (ici, eu-west-3) puis cliquez sur Créer une fonction :
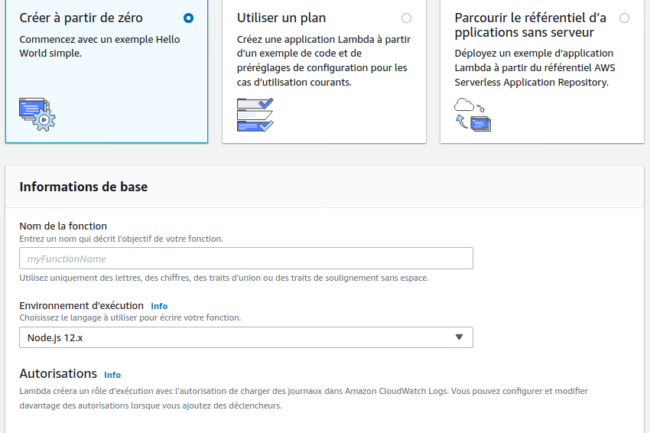
Il est possible à ce stade de déployer une fonction existante, en parcourant par exemple la liste des applications publiques mais nous partirons de zéro, afin de déployer notre propre application. A l’heure actuelle (15-09-2020), les langages supportés sont les suivants :
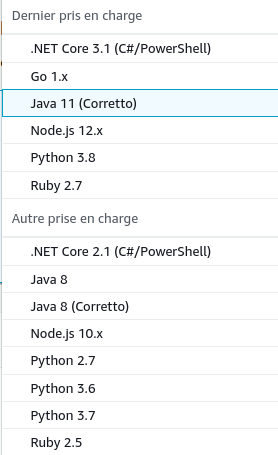
Node.js 12.x est le langage par défaut et bénéficie d’un éditeur en ligne, directement intégré à la console AWS. Nous choisirons Java 11 pour notre projet.
Le nom de la fonction est obligatoire. Il n’existe pas à ce sujet de convention de nommage explicite. J’ai choisi pour ma part keywords-extractor de manière à représenter sans ambiguïté le « métier » exercé.
Il est possible de définir ou d’attacher à la fonction un rôle existant dans la section Autorisations. Nous garderons le choix par défaut « Créer un nouveau rôle avec les autorisations Lambda de base » :
Configuration
La deuxième étape est importante à bien des égards. Elle nous permet d’une part de préciser la classe et la méthode utilisées comme point d’entrée de la fonction et d’autre part de paramétrer les ressources du conteneur au sein duquel la fonction sera exécutée. Ouvrez la section Paramètres de base :
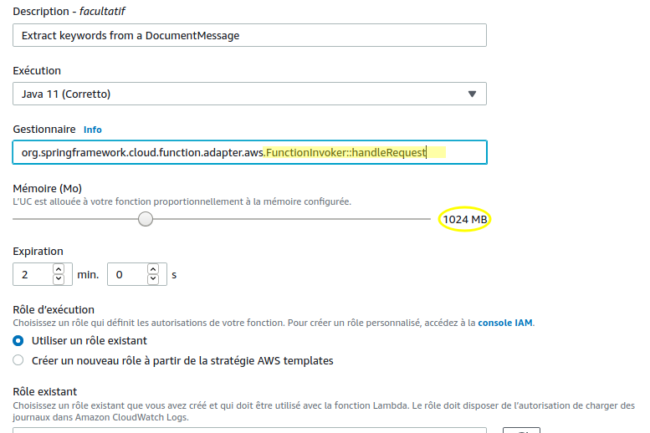
Comme précisé dans la documentation de Spring Cloud Function, l’adaptateur AWS dispose de gestionnaires de requêtes génériques implémentant l’interface RequestStreamHandler. Il est possible de créer son propre handler, à l’exemple de cet extrait de code, issu de la documentation d’AWS mais les handlers génériques fournis par Spring feront pour le moment l’affaire. Le format utilisé ici est celui des « method reference » de Java 8, appelé « Full format » dans l’aide d’Amazon (package.Class::method).
L’un des paramètres les plus importants concerne la gestion de la mémoire. La quantité de mémoire allouée influe directement sur la puissance du processeur et par conséquent sur le temps global d’exécution. Sachant que le tarif dépend également de cette quantité, il est nécessaire néanmoins de trouver un bon compromis en tenant compte du budget consenti et des statistiques d’utilisation. Un calculateur de tarifs est destiné à cet usage : pricing-calculator.
Ci-dessous, un échantillon des performances en fonction de la quantité de mémoire allouée :
|
Mémoire allouée |
Durée |
Durée facturée |
Mémoire max utilisée |
Durée d’initialisation |
Conteneur activé |
|---|---|---|---|---|---|
|
256 MB |
1377.89 ms |
1400 ms |
152 MB |
3696.88 ms |
x |
|
512 MB |
581.68 ms |
600 ms |
152 MB |
3676.54 ms |
x |
|
1024 MB |
296.09 ms |
300 ms |
156 MB |
3611.00 ms |
x |
|
1024 MB |
2.11 ms |
100 ms |
132 MB |
|
o |
La durée facturée (Billed Duration) est inversement proportionnelle à la quantité de mémoire allouée. Avec 1024 MB, le temps d’exécution (facturé) à froid n’est plus que de 300ms, alors qu’il atteint 1400ms avec 256 MB. A chaud, conteneur encore actif, le temps d’exécution est encore plus faible. Dans l’exemple, bien que la mémoire utilisée soit toujours en-dessous de 160 MB, il y a un clair avantage à en allouer 1024.
Signalons enfin le paramètre de temps d’expiration (Expiration time) correspondant à la durée maximale d’exécution de la fonction. Sa limite est aujourd’hui fixée à 15 minutes. Ce paramètre ne doit pas être confondu avec la durée de vie du conteneur (l’instance sur laquelle la fonction est exécutée), gérée de manière opaque par la plateforme et qui permet d’éviter les redémarrages à froid.
La durée de vie d’un conteneur, bien que pouvant s’étendre jusqu’à 45 minutes, est très variable et ne peut être prise en compte à elle seule pour évaluer les performances d’une Lambda.
Importation du code
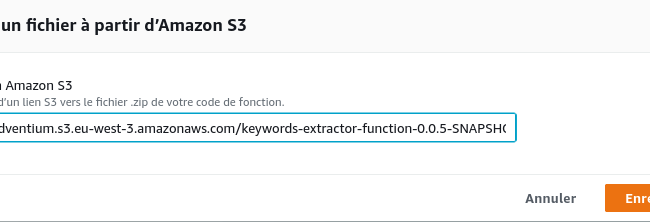
La troisième étape consiste à déployer le code importé dans la section Code de fonction. Deux choix sont possibles suivant la taille de l’objet importé. Bien que l’on puisse charger des fichiers de plus de 10 M, Amazon juge préférable de les enregistrer au préalable dans un compartiment (bucket) S3. Comme le JAR dépassait 13 M, j’ai choisi cette dernière option. Je ne m’étendrais pas sur l’ajout de ressources dans S3, mais cette opération effectuée, le fichier peut être automatiquement récupéré en lui donnant son URL :
Test
Il ne reste plus qu’à tester notre fonction. Comme nous l’avons vu plus haut, oublier de déclarer dans le manifest la classe principale de l’application conduit à l’erreur suivante lors de l’exécution des tests :
{
"errorMessage": "Failed to discover main class. An attempt was made to discover main class as 'MAIN_CLASS' environment variable, system property as well as entry in META-INF/MANIFEST.MF (in that order).",
"errorType": "java.lang.IllegalStateException"
}
Dans ce cas, il est possible, comme indiqué, de déclarer la variable d’environnement MAIN_CLASS dans la section Variables d’environnement de la console.
On peut ajouter jusqu’à 10 tests. Cliquez sur Configurer des événements de test . Un événement de test est un simple nom associé à un payload (optionnel), représentant l’objet en entrée de la fonction. Cet objet est au format JSON et dans notre exemple, il correspond aux données du DocumentMessage dont nous parlions en début d’article :
{
"reference": {
"key": "2",
"location": "none"
},
"content": "Un CV de démonstration comportant quatre mots clés : Java, php, css, javascript",
"keywords": ["css", "javascript", "java 8"]
}
Après création de l’événement, cliquez sur Tester pour lancer la fonction. Le démarrage à froid prendra peut prendre d’une à plusieurs secondes suivant la complexité du projet mais si tout se passe bien, vous aurez droit à une fenêtre de résultats de ce type :
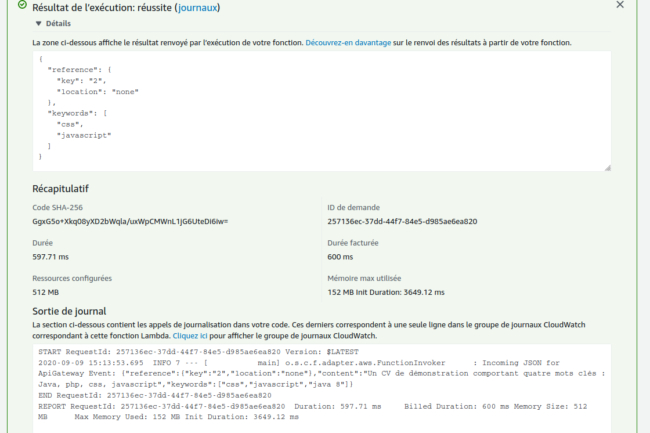
Profitons-en pour signaler que des journaux (logs) sont également disponibles dans Cloudwatch, l’équivalent de Kibana pour Amazon. Un « groupe de journaux », intitulé /aws/lambda/keywords-extractor a été automatiquement créé et peut être librement consulté sur la page idoine en cliquant sur le lien journaux.
Ajout d’un déclencheur
Tester, c’est bien, mais on aimerait maintenant pouvoir démarrer notre fonction indépendamment de la console, à partir d’un stimuli externe, en tant que réponse à un appel REST, par exemple. Amazon nous donne le moyen de le faire au moyen d’un déclencheur (trigger) et en en choisissant un parmi les nombreux types proposés. Cliquez pour cela sur Ajouter un déclencheur dans la section Designer de la console. Amazon nous donne le choix entre les déclencheurs natifs de la plateforme et ceux issus des éditeurs partenaires.
Mise en service de l’API Gateway
Le premier de la liste, API Gateway, est celui qui nous intéresse. Ce service Amazon permet de router l’envoi et la réception de messages HTTP en les encapsulant dans des objets de type provy event et dont voici un aperçu dans le cas d’une requête :
{
"version": "2.0",
"routeKey": "ANY /keywords-extractor",
"rawPath": "/default/keywords-extractor",
"rawQueryString": "",
"headers": {
"accept": "*/*",
"accept-encoding": "gzip, deflate",
"authorization": "AWS4-HMAC-SHA256 Credential=AKIAVJBVAYF333GTHCQB/20200914/us-east-1/execute-api/aws4_request, SignedHeaders=cache-control;content-length;content-type;host;x-amz-date, Signature=a690a8ff1794354878a43f74872967466817267450a6e51b315b746a7dc2f5fa",
"cache-control": "no-cache",
"content-length": "254",
"content-type": "application/json",
"host": "d3rg0sszqf.execute-api.eu-west-3.amazonaws.com",
"user-agent": "PostmanRuntime/7.4.0",
"x-amz-date": "20200914T112506Z",
"x-amzn-trace-id": "Root=1-5f5f5312-163e6e16bebad0723033a46a",
"x-forwarded-for": "91.165.26.56",
"x-forwarded-port": "443",
"x-forwarded-proto": "https"
},
"requestContext": {
"accountId": "363035935095",
"apiId": "d3rg0sszqf",
"domainName": "d3rg0sszqf.execute-api.eu-west-3.amazonaws.com",
"domainPrefix": "d3rg0sszqf",
"http": {
"method": "POST",
"path": "/default/keywords-extractor",
"protocol": "HTTP/1.1",
"sourceIp": "91.165.26.56",
"userAgent": "PostmanRuntime/7.4.0"
},
"requestId": "S2nq7gXVCGYEPyg=",
"routeKey": "ANY /keywords-extractor",
"stage": "default",
"time": "14/Sep/2020:11:25:06 +0000",
"timeEpoch": 1600082706689
},
"body": "{\n\"reference\": {\n \"key\": \"2\",\n\"location\": \"none\"\n},\n\"content\": \"Un CV de démonstration comportant quatre mots clés : Java, php, css, javascript\",\n \"keywords\": [\n\"css\",\n \"javascript\",\n \"java 8\"\n ]\n}",
"isBase64Encoded": false
}
La destination de la requête est spécifiée par les propriétés route-key et rawPath, en l’occurrence, la ressource keywords-extractor dans l’environnement par défaut. Le corps original de la requête correspond à la valeur littérale de la propriété body. N’importe quel type de requête (GET, POST, PUT, etc.) est ici accepté, c’est le sens du mot clé ANY dans la valeur de route-key.
Après avoir sélectionné API Gateway dans les types de déclencheur, il nous est possible d’attacher une API existante ou d’en créer une de toutes pièces. Prenons la première option et choisissons API HTTP pour son type :
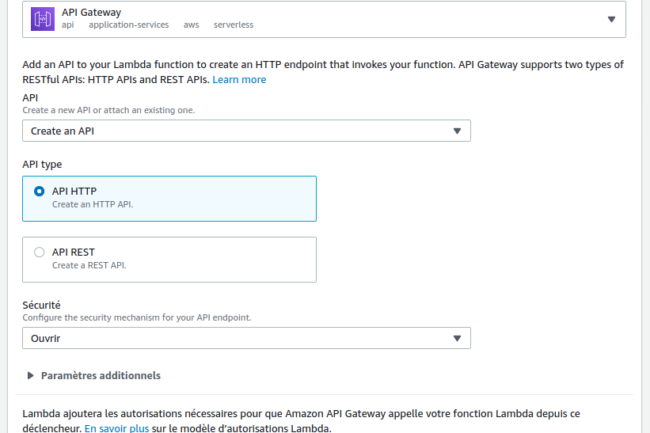
Selon Amazon, l’HTTP API, version allégée de l’API REST, est plus appropriée dans le cadre d’une fonction Lambda en raison entre autres de son coût et de sa faible latence.
Sous le champ Sécurité nous avons le choix entre Ouvrir ou Create JWT authorizer. Le premier choix nous permet d’effectuer des requêtes sans avoir à fournir de jeton d’autorisation.
Si l’on ne précise pas de paramètres additionnels, le nom de l’API sera celui de la fonction suffixé par API et l’étape de déploiement prendra pour valeur default. Il est possible après coup d’ajouter d’autres étapes comme dev ou staging par exemple.
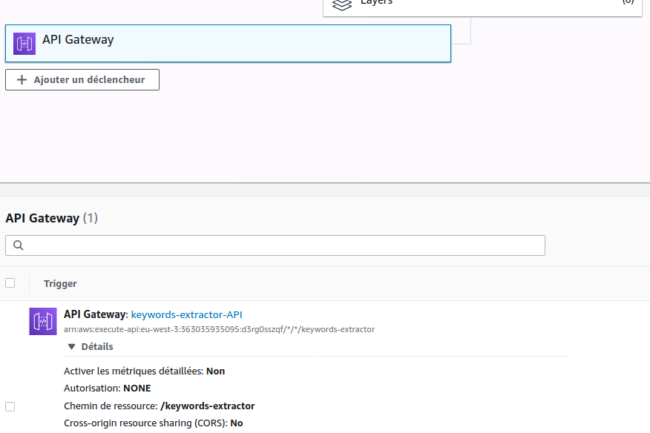
Après avoir cliqué sur Ajouter, on peut accéder aux détails du déclencheur dans la console, et récupérer notamment l’URL d’appel HTTP :
Test de l’API Gateway
Il ne nous reste plus qu’à tester notre requête dans Postman :
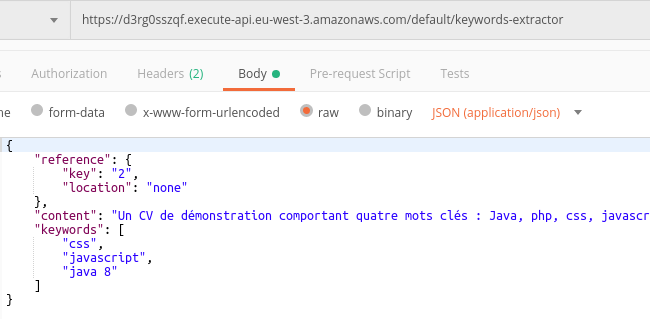
J’utilise ici la méthode POST mais j’aurais très bien pu utiliser GET ou toute autre méthode, la fonction Lambda ayant été configurée pour accepter n’importe quel type de requête (ANY). Rien n’interdit à ce sujet d’envoyer un body avec la méthode GET.
Il semblerait que notre body n’ait pas été pris en compte. Compte tenu du message envoyé, la référence et la liste de mots clés ne devraient pas être nuls :
{
"reference": null,
"keywords": []
}
C’est d’autant plus troublant que le test dans la console continue de renvoyer un résultat positif :
{
"reference": {
"key": "2",
"location": "none"
},
"keywords": [
"css",
"javascript"
]
}
Voici le fin mot de l’histoire : l’Event envoyé par l’API est de type Proxy Event, autrement dit un message encapsulant les données de la requête d’origine. Or, le handler générique (FunctionInvoker) que nous avions configuré pour notre Lambda ne prend pas en charge ce type d’objet. Il faut pour y remédier utiliser l’implémentation plus spécifique SpringBootApiGatewayRequestHandler.
FunctionInvoker implémente l’interface RequestStreamHandler alors que SpringBootApiGatewayRequestHandler hérite de SpringBootRequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent>.
On le réalise mieux en comparant le code de la méthode handleRequest dans les deux implémentations.
FunctionInvoker
@Override public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException { Message requestMessage = this.generateMessage(input, context); Message<byte[]> responseMessage = (Message<byte[]>) this.function.apply(requestMessage); byte[] responseBytes = responseMessage.getPayload(); ...
SpringBootApiGatewayRequestHandler
@Override public Object handleRequest(APIGatewayProxyRequestEvent event, Context context) { Object response = super.handleRequest(event, context); if (returnsOutput()) { return response; } else { return new APIGatewayProxyResponseEvent() .withStatusCode(HttpStatus.OK.value()); } }
La classe APIGatewayProxyRequestEvent provenant de la librairie aws-lambda-java-events, il ne faut pas oublier d’ajouter cette dépendance dans le pom de l’application et de mettre à jour le JAR de déploiement (mvn package) :
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-events</artifactId> <version>3.2.0</version> </dependency>
Après avoir modifié le handler dans la configuration de la Lambda et redéployé le code du projet, le résultat renvoyé par Postman est désormais correct :
{"reference":{"key":"2","location":"none"},"keywords":["css","javascript"]}
Cependant, le test dans la console AWS ne fonctionne plus :
{
"errorMessage": "class java.util.Optional cannot be cast to class com.adventium.keywords.extractor.model.DocumentMessage (java.util.Optional is in module java.base of loader 'bootstrap'; com.adventium.keywords.extractor.model.DocumentMessage is in unnamed module of loader lambdainternal.CustomerClassLoader @5b480cf9)",
"errorType": "java.lang.ClassCastException",
C’est en raison des données envoyées. Le handler s’attend à recevoir un objet du type APIGatewayProxyRequestEvent mais on lui envoie le type brut initial correspondant au DocumentMessage. Il faut modifier l’événement de test afin qu’il envoie le payload suivant :
{
"body": "{\"reference\":{\"key\":\"2\",\"location\":\"none\"},\"content\":\"Un CV de démonstration comportant quatre mots clés : Java, php, css, javascript\",\"keywords\":[\"css\",\"javascript\",\"java 8\"]}"
}
Comme nous l’avons vu plus haut, le corps de la requête est encapsulé sous forme de chaîne dans la propriété body de l’événement. Il a fallu ici « stringifier » le JSON original pour qu’il puisse correspondre au format attendu.
La réponse renvoyée par les tests est maintenant de ce type :
{
"statusCode": 200,
"body": "{\"reference\":{\"key\":\"2\",\"location\":\"none\"},\"keywords\":[\"css\",\"javascript\"]}"
}
Cette absence de corrélation entre les tests en console et ceux effectués en externe peut paraître très troublante au premier abord. Mais on finit par en comprendre la logique avec un peu d’habitude.
La mise en place d’une fonction Lambda au sein d’AWS nécessite on le voit quelques ajustements et peut paraître assez fastidieuse lors des premières utilisations. On en réservera l’usage aux services s’exécutant fréquemment et à l’environnement assez léger afin que les bénéfices de cette infrastructure l’emportent sur ses inconvénients. A ce titre, l’utilisation d’un framework comme Spring n’est peut-être pas la plus appropriée et des solutions basées sur Quarkus ou NodeJs pourraient se révéler plus avantageuses.