
Le paradigme fonctionnel au service de l’Event Driven
L’Event Driven Design est aujourd’hui l’architecture privilégiée au sein d’un environnement micro-services. Ceux-ci y sont considérés comme des entités autonomes, ne communiquant pas directement entre eux et suffisamment indépendants pour que la panne de l’un d’eux ne corrompe le fonctionnement de l’ensemble. Cette architecture repose en grande partie sur la présence de « Brokers » de messages, chargés de router les événements et de les envoyer de manière asynchrone aux différents souscripteurs.
Ces Brokers disposent de leur propre éco-système et leur intégration au sein des applications se fait par l’intermédiaire de librairies spécifiques. Cela pose cependant des problèmes de productivité car le passage d’un Broker à un autre implique la réécriture d’une partie du code. Spring Cloud Stream pallie à cet inconvénient en proposant une interface commune de communication, chargée de la mise en relation avec les différents Brokers existants. Pour l’heure, seuls RabbitMQ et Kafka sont pris en charge mais on peut en espérer d’autres à l’avenir.
Exemple de scénario
Afin d’illustrer son utilisation, prenons l’exemple de scénario suivant :
- Un CV est uploadé puis enregistré en base de données.
- Un message sortant est alors envoyé au broker par le gestionnaire de CV (cv-service).
- Le service d’extraction de mots clés (keywords-extractor) est à l’écoute de ce message. L’extraction est lancée dès sa réception.
- La liste des mots clés obtenus est encapsulée dans un message sortant
- Les services à l’écoute peuvent réagir à la réception de ce dernier message. Parmi eux, le gestionnaire de CV se contente d’afficher la liste des mots clés résultants.
Voilà une manière de le représenter :
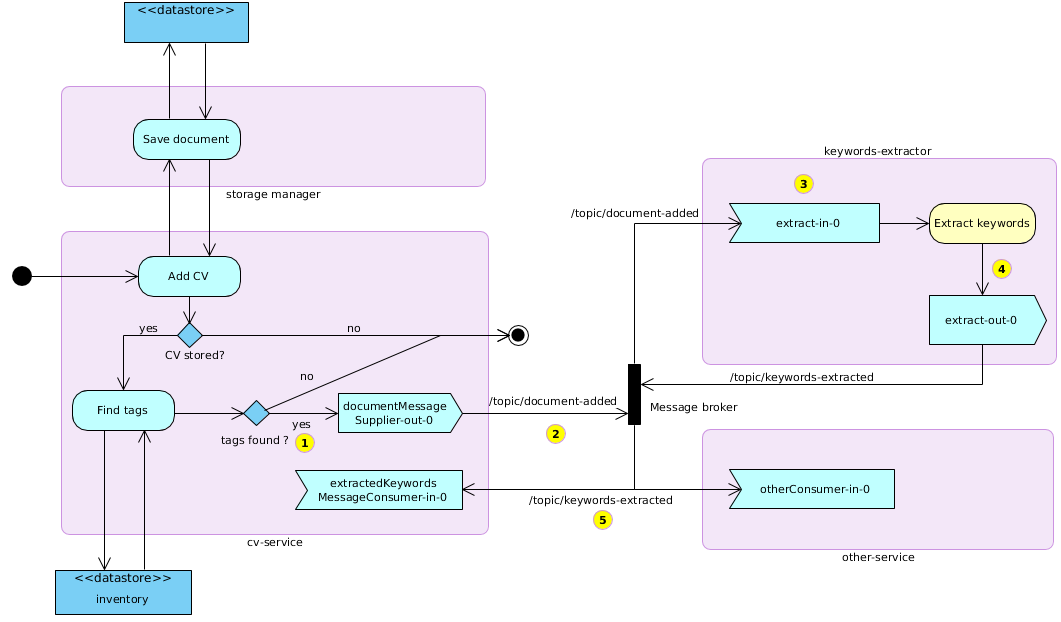
Architecture de base
Nous allons pour l’instant nous concentrer sur deux services : un gestionnaire de CV et un extracteur de mots clés. Ces deux services communiqueront par l’intermédiaire de RabbitMQ, l’un des Brokers de référence. Ils auront pour noms respectifs cv-service et keywords-extractor.
Installation de RabbitMQ
La solution la plus simple est d’utiliser Docker. Une seule commande suffit pour installer et démarrer le service :
docker run -d --hostname local-rabbit --name demo-rmq -p 15672:15672 -p 5672:5672 rabbitmq:3.8.3-management-alpine
Le service peut être arrêté ainsi :
docker stop demo-rmq
et redémarré à l’aide de la commande suivante :
docker start demo-rmq
L’interface d’administration de RabbitMQ est disponible à cette adresse :
http://localhost:15672
guest guest sont les identifiants par défaut.
Connexion
Les paramètres de connexion dépendant du broker utilisé, nous donnerons pour ce dernier une valeur aux variables suivantes :
spring.rabbitmq.host
spring.rabbitmq.port
spring.rabbitmq.username
spring.rabbitmq.passwordhost et port n’ont pas besoin d’être spécifiés s’ils correspondent aux valeurs par défaut reconnues par Spring : localhost et 5672.
Pour Kafka, les noms d’hôte correspondent au paramètre :
spring.cloud.stream.kafka.binder.brokers
Les deux services faisant appel au Broker, ces paramètres doivent être renseignés pour chacun d’eux.
Il y tout intérêt à renseigner ces paramètres à l’aide de variables d’environnement. Plutôt que de les configurer dans le fichier application.properties (ou application.yml), on prendra soin d’exporter ces variables au démarrage de l’application.
Ex. :
export SPRING_RABBITMQ_USERNAME=guest
La manière de déclarer ces variables dépendra de la plateforme et des outils de déploiement sélectionnés. En développement, on peut par exemple les déclarer dans le configurateur de démarrage de son IDE (comme ci-dessous avec Intellij) :
Configuration du gestionnaire de CV
Dans application.properties :
spring.cloud.stream.source=document-added
spring.cloud.stream.bindings.extractedKeywordsMessageConsumer-in-0.destination=keywords-extracted
Ici, l’envoi de message ne dépend pas de la réception d’un événement. Il s’agit d’un message initial. C’est ce qu’indique la ligne spring.cloud.stream.source=document-added. La source de données provient en effet d’un appel REST – http://localhost:8080/cv :
@PostMapping public ResponseEntity<CvDocument> addCV( @RequestBody CvDocument cv, UriComponentsBuilder uriComponentsBuilder)
Le bout de code suivant permet de faire cet envoi :
streamBridge.send("document-added-out-0", messageFrom(cvDocument));
org.springframework.cloud.stream.function.StreamBridge est un composant (Bean) fourni par l’API Spring Cloud Stream. Il permet comme son nom l’indique d’encapsuler la source de données dans un message (un « stream ») afin de pouvoir l’envoyer vers une destination prédéfinie.
La ligne spring.cloud.stream.bindings.extractedKeywordsMessageConsumer-in-0.destination=keywords-extracted correspond quant à elle au message de réception des mots-clés, issu du service d’extraction. in-0 est une convention d’écriture représentant les données entrantes, représentées par le premier argument de la fonction (à l’index 0, donc).
extractedKeywordsMessageConsumer référence le nom du Bean « consommant » ce message. Dans la terminologie Java, ce Bean correspond à une interface fonctionnelle. Un Consumer prend un objet en paramètre mais ne retourne rien. Dans l’extrait de code suivant, le consumer est représenté par l’expression lambda message -> log.info(message.toString()) :
@Bean public Consumer<ExtractedKeywordsMessage> extractedKeywordsMessageConsumer() { return message -> log.info(message.toString()); }
Le nom du Bean correspond ici au nom de la méthode chargée de le renvoyer. C’est une convention de nommage implicite dans le cadre du framework Spring.
Configuration de l’extracteur de mots clés
Dans application.properties :
spring.cloud.stream.bindings.extract-in-0.destination=document-added-out-0
spring.cloud.stream.bindings.extract-out-0.destination=keywords-extracted
Comme vu précédemment, extract est l’identifiant du Bean chargé de réceptionner le message et d’y répondre en retour. C’est la raison pour laquelle ce nom est suffixé par out-0 dans le cas de l’envoi et par in-0 (dans le cas de la réception). Cela repose sur une convention de nommage du framework Spring Cloud Stream. Plus haut, nous utilisions document-added-out-0 pour signifier l’envoi d’un document. Ici, nous seront aussi à l’écoute d’un message en retour, extract-in-0. Ce double échange est implémenté au moyen d’une interface fonctionnelle de type Function. Le chiffre 0 correspond au premier argument de la méthode retournée :
@Bean public Function<DocumentMessage, ExtractedKeywordsMessage> extract() { return extractorService::extract; }
La fonction (au sens strict du terme) reçoit en paramètre un objet de type DocumentMessage et en retourne un autre du type ExtractedKeywordsMessage. Ces objets associent au contenu proprement dit du message des propriétés permettant de faciliter leur traitement, la référence du document par exemple, autrement dit le moyen d’associer ce document à une personne ou à une adresse, s’il faut le retrouver par la suite :
public class DocumentMessage { private Reference reference; private String content; private List<String> keywords; } --- public class ExtractedKeywordsMessage { private Reference reference; private Set<String> keywords; }
Si l’on utilisait par exemple AWS S3, la référence pourrait permettre de récupérer le nom et l’emplacement du document (key et bucket).
L’extraction proprement dite fait appel à l’objet métier KeywordsExtractor. En voici un exemple d’implémentation :
public class KeywordsExtractor implements Extractor { private static final String WORD_BOUNDARY_PREFIX = "(?i)\\b("; private static final String WORD_BOUNDARY_SUFFIX = ")\\b"; private DocumentMessage message; public Set<String> extract() { if (message == null || CollectionUtils.isEmpty(message.getKeywords()) || StringUtils.isEmpty(message.getContent())) { return new TreeSet<>(); } String regex = message.getKeywords().stream().collect(joining("|", WORD_BOUNDARY_PREFIX, WORD_BOUNDARY_SUFFIX)); Matcher matcher = Pattern.compile(regex).matcher(message.getContent()); return matcher.results().map(MatchResult::group).collect(toCollection(TreeSet::new)); } }
Logs
Traçage des appels après le POST :
{ "reference": { "key": "2", "location": "none" }, "category" : "IT" }
Note : un contenu par défaut est généré par l’application en son absence.
-
- Envoi du message initial :
Result of invocation of "document-added-out-0" function...
Applying type conversion on output value
preSend on channel 'bean 'document-added-out-0''... - Réception du message par le service d’extraction. Le contenu du message est associé à une liste de mots clés de référence sur laquelle on se basera pour récupérer ceux qui sont présents dans le document :
c.f.c.c.BeanFactoryAwareFunctionRegistry : Applying type conversion on input value GenericMessage
c.a.k.service.ExtractorServiceImpl : Document received : DocumentMessage(reference=1234 none, keywords=[java 8, Javascript, Eclipse, tomcat, postgresql, css, spring boot]) - Résultat de l’extraction :
c.f.c.c.BeanFactoryAwareFunctionRegistry : Result of invocation of "extract" function is 'Document (1234 none), extracted keywords :[css, eclipse, java 8, javascript, spring boot]' - Réception de l’extraction :
c.f.c.c.BeanFactoryAwareFunctionRegistry : Applying function: extractedKeywordsMessageConsumer
Converted from Message: Document (1234 none), extracted keywords :[spring boot, css, java 8, javascript, eclipse]
- Envoi du message initial :
Représentation RabbitMQ
Bien que le cheminement soit présenté ici de manière séquentielle, les opérations ne sont pas bloquantes. L’envoi ou la réception des messages pourront prendre plus de temps que prévu et interviendront au moment le plus favorable sans perturber le cycle de vie des applications. C’est l’une des différences fondamentales de ce type d’achitecture asynchrone par rapport au schéma HTTP request-response traditionnel.
Les files d’attente et les sujets de ces messages (Exchange) apparaissent ainsi dans l’interface de RabbitMQ :
Liste des exchanges
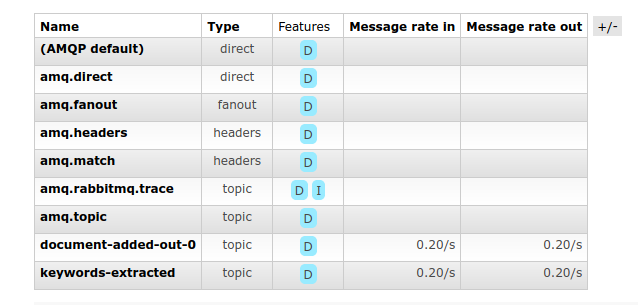
Liste des files d’attente

Les Exchanges permettent de router les messages entrants et sortants vers les files d’attente. On reconnaît ici les deux destinations spécifiées dans les « properties » des deux services : document-added-out-0 et keywords-extracted.
Si elles sont marquées comme « durables », les files d’attente peuvent être récupérées après un redémarrage du Broker. Les messages encore non transmis resteront ainsi disponibles.
Implémentation Reactive
Afin d’assurer plus de concordance au sein de cet environnement asynchrone, Spring Cloud Stream nous permet de profiter du paradigme Reactif grâce à l’intégration de la librairie Reactor. Il est ainsi possible de réécrire les fonctions précédentes en tirant notamment parti de la classe Flux, implémentant l’interface Publisher.
Lorsque la source de données est d’origine externe, c’est le cas ici puisqu’elle provient d’un appel REST, deux mécanismes peuvent être utilisés suivant le modèle de programmation mis en œuvre :
-
-
- le recours au Bean préconfiguré
StreamBridge, comme nous l’avons vu plus haut pour le modèle impératif - l’intervention d’un
EmitterProcessor, pour le modèle réactif
- le recours au Bean préconfiguré
-
C’est ce dernier auquel nous ferons appel ici par l’intermédiaire d’un Supplier<Flux<DocumentMessage>>. Contrairement à un Supplier conventionnel, celui-ci retourne un Flux et ne sera déclenché qu’une fois (triggered) par le framework :
private final EmitterProcessor<DocumentMessage> processor = EmitterProcessor.create(); public void sendDocument(CvDocument cvDocument) { processor.onNext(messageFrom(cvDocument)); } @Bean public Supplier<Flux<DocumentMessage>> documentMessageSupplier() { return () -> processor; }
Il n’est plus nécessaire dans ce cas de déclarer comme auparavant la source de données dans la configuration :
#spring.cloud.stream.source=document-added
Mais il ne faut pas oublier par contre d’indiquer cette destination dans le binding de la fonction :
spring.cloud.stream.bindings.documentMessageSupplier-out-0.destination=document-added-out-0
Enfin, le service faisant appel à plus d’une seule fonction de streaming, il est nécessaire de les déclarer, en les séparant par un point-virgule, par l’intermédiaire de la propriété spring.cloud.function.definition :
spring.cloud.function.definition=documentMessageSupplier;extractedKeywordsMessageConsumer
Côté cv-service, le consumer peut être réimplémenté ainsi :
@Bean public Consumer<Flux<ExtractedKeywordsMessage>> extractedKeywordsMessageConsumer() { return flux -> flux.subscribe(message -> log.info(message.toString())); }
Il ne faut pas oublier dans ce cas de souscrire au flux renvoyé sous peine de n’obtenir aucun résultat.
La documentation de Spring Cloud propose une syntaxe alternative au Consumer précédent :
@Bean public Function<Flux<ExtractedKeywordsMessage>, Mono<Void>> extractedKeywordsMessageConsumer() { return flux -> flux.log().then(); }
Un « Consumer » ne retournant rien, la valeur de retour de la fonction est ici représentée par l’appel de la fonction then() qui renvoie un Mono de Void.
Côté extracteur, le Bean fonctionnel peut être réécrit comme suit :
@Bean Function<Flux<DocumentMessage>, Flux<ExtractedKeywordsMessage>> extract() { return flux -> flux.map(extractorService::extract); }
Le flux entrant est « remappé » pour qu’il puisse retransmettre un objet de type ExtractedKeywordsMessage.
Conclusion
Grâce aux mécanismes que nous venons de décrire, il n’y a aucun lien direct entre le gestionnaire de CV et l’extracteur de mots clés. Les trois objectifs initiaux sont atteints :
- réduire le couplage entre les composants
- isoler les responsabilités de chaque service
- améliorer la résilience
En s’appuyant d’une part sur une syntaxe déclarative relativement claire et concise et d’autre part sur le paradigme fonctionnel, Spring Cloud Stream facilite grandement l’écriture d’applications asynchrones et réduit la courbe d’apprentissage liée à l’utilisation de tel ou tel Broker de messages. Grâce à cet ensemble d’outils, il n’y a plus de freins au développement de projets de type micro-services.