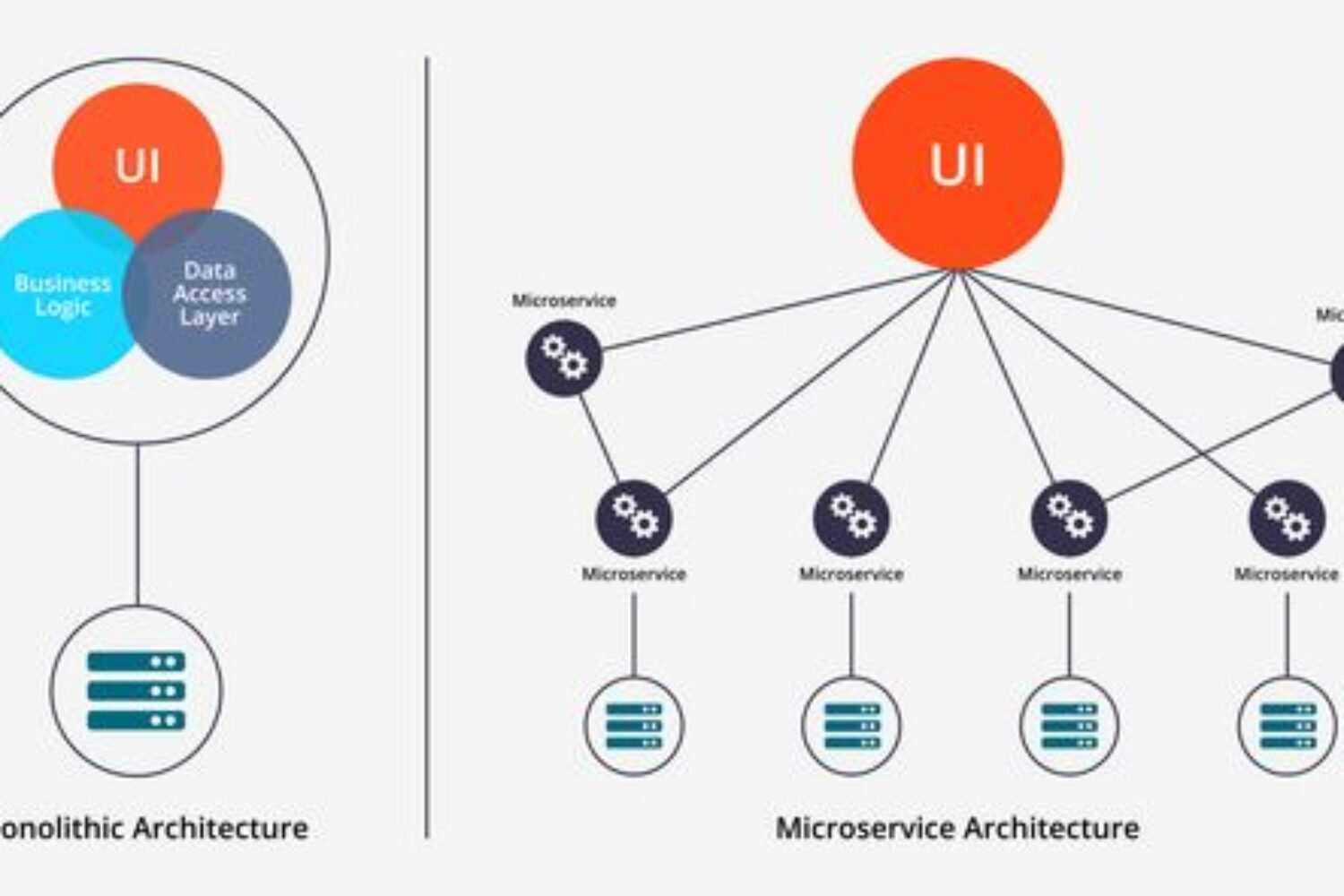
Introduction
Découper une application en micro-services, c’est appliquer le concept « Diviser pour régner ». Le principe général est de construire un ensemble de blocs, assez indépendants les uns des autres pour que la dégradation de l’entre d’entre eux ne perturbe pas le fonctionnement de ceux encore à disposition. Comme précisé dans le livre blanc de Redhat [1] : « Chaque microservice est alors géré et déployé de façon indépendante, potentiellement par différentes équipes responsables de leur cycle de vie ». Chaque équipe se voyant attribuer un périmètre bien défini, cela réduit considérablement les risques et la complexité de mise en œuvre, du développement à l’exploitation.
Communication
Ces services une fois délimités, il est la plupart du temps nécessaire de les faire communiquer. Deux solutions sont généralement utilisées dans ce but :
- communication par API
- envoi de messages
La première est réalisée au moyen de l’architecture REST. S’appuyant sur le protocole HTTP, par essence sans états, ce style d’architecture répond significativement aux exigences du Cloud.
Les réponses aux requêtes peuvent par ailleurs être regroupées à l’aide de passerelles (API Gateway) pour satisfaire les attentes du client, notamment lorsqu’il s’agit d’applications mobiles. Les librairies de type « Reactive » prennent tout leur intérêt dans ces contextes où les données, provenant de plusieurs endroits et véhiculées sous divers protocoles, ne peuvent être récupérées de manière synchrone.
La seconde se distingue par son caractère asynchrone. Elle est à privilégier lorsque les temps d’attente de réponses ne sont pas décisifs ou que celles-ci sont optionnelles. La communication par message permet également de s’adresser à plusieurs destinataires. On peut obéir pour cela à des mécanismes de publication/abonnement, comme le préconise le style d’architecture Event-driven.
Orchestration et Chorégraphie sont souvent employés pour les distinguer. Bien que l’analogie musicale ait ses limites, les deux termes n’étant pas comparables en réalité, elle a le mérite de donner une image assez parlante des interactions mises en place. Dans le premier cas, les services dépendent d’un conducteur, un « chef d’orchestre », qui va centraliser les demandes et attendre le retour des services invoqués pour envoyer sa réponse. Dans le second cas, chaque participant répond indépendamment aux sollicitations de ses pairs, à l’instar des danseurs dans une troupe.
Quelle que soit le type de communication utilisé, Microsoft rappelle dans sa documentation [2] la règle essentielle suivante : « …la communication entre les microservices doit être asynchrone ». Cela ne signifie pas qu’il faut bannir le protocole HTTP mais comme précisé, d’« …effectuer la communication entre microservices par propagation asynchrone des données, tout en essayant de ne pas dépendre d’autres microservices internes… ».
Afin de limiter les dépendances entre services, et d’éviter ainsi de coûteuses séquences d’appels, il est conseillé d’en répliquer les données significatives dans des bases distinctes. En admettant par exemple qu’un service de facturation partage des données de contact avec le service d’administration de compte, on peut imaginer que chacun d’eux dispose de sa propre base, alimentée et mise à jour de manière automatique à partir d’un tronc commun.
Dans le cas où ces bases ne nécessitent pas d’écriture, on pourra tirer profit du pattern CQRS (Command Query Responsibility Segregation). Comme son acronyme le suggère, le but de ce pattern est de dissocier lecture (Query) et persistence de données (le C de Command). Le modèle de données sous-jacent pourra varier suivant le type d’opérations : base de données NoSQL pour la lecture, SGBD relationnel pour l’écriture. Cela permettra non seulement d’améliorer les temps de réponse mais aussi de dissocier dans le code les patterns dédiés à la simple consultation de ceux dédiés à la persistance.
Lorsque le nombre de services ou d’interactions est très élevé [3] (une société comme Netflix utilise par exemple plusieurs centaines de micro-services), on peut envisager de construire un réseau maillé (service mesh). Comme précisé par Redhat [4], « L’acheminement des requêtes entre les microservices s’effectue via des proxies situés sur leur propre couche d’infrastructure ». Cela permet de découpler les services des problèmes d’acheminement et de configuration engendrés par l’accroissement du réseau.
Graceful Degradation
Le concept de « graceful degradation » a été popularisé par les ingénieurs d’Heroku et fait désormais partie des fameux Douze facteurs.
La manière de réagir à la dégradation d’un service est habilement illustrée dans ce schéma d’OCTO Technology [5] :
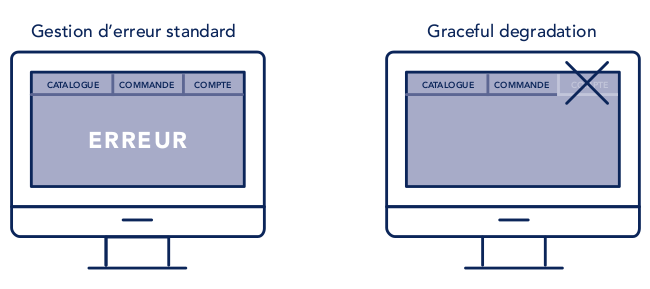
Dans l’image de droite, l’indisponibilité du processus se traduit simplement par la désactivation du bouton d’accès. Il n’y a pas de rupture de flux, contrairement à l’exemple de gauche. Le catalogue ou la commande continuent d’être disponibles, l’erreur ne touchant que l’îlot dédié au compte. A gauche, l’erreur est non seulement difficile à identifier mais aussi bloquante. Dans le cadre d’une application cloud-native, le pattern de droite est le plus approprié, cela va de soi.
Patterns
De nombreux modèles modèles de conception sont apparus afin d’optimiser l’usage des micro-services dans un environnement Cloud. Certains d’entre eux sont particulièrement adaptés aux problèmes de résilience [6].
Circuit Breaker
Le Circuit Breaker (Coupe-circuit, dans sa traduction littérale) est l’un de ceux les plus utilisés. Le but de ce pattern est d’éviter qu’une application continue d’effectuer une opération si celle-ci est susceptible de défaillances. On se base sur trois états : fermé, ouvert, semi-ouvert. Dans l’état fermé, le nombre de défaillances est enregistré dans un compteur. Si le décompte atteint un seuil spécifié, le circuit est ouvert et l’opération n’est plus exécutée (le courant ne passe plus). Après un timeout d’une durée reconfigurable, le circuit est à nouveau refermé après être passé par l’état semi-ouvert intermédiaire.
Comme le constate Werner Vogels, CTO d’Amazon [7] : « Failures are a given and everything will eventually fail over time » (les défaillances sont inéluctables et tout finit par tomber en panne). C’est d’autant plus vrai dans le cadre du Cloud Computing, axé sur les notions de réversibilité et d’impermanence.
Afin d’anticiper les dysfonctionnements et d’éviter les blocages qu’ils entraînent, il est intéressant de concevoir nos applications avec la notion de Design for failure. Suivre ce modèle de conception c’est permettre aux applications de rester disponibles même si l’infrastructure matérielle est hors service. La prévention contre les pannes, directement intégrée aux blocs applicatifs, n’est plus ainsi de la responsabilité exclusive du système sous-jacent (répartition de charge, redondance, etc.).
Bulkhead
Le pattern Bulkhead s’inspire de la manière dont les navires se protègent des naufrages grâce à leur coque divisée en plusieurs sections. Si l’une de ces sections venait à prendre l’eau, les autres, en restant étanches permettraient au navire de continuer sa route, de manière dégradée certes, mais en l’empêchant néanmoins de couler.
L’idée est de répartir les instances de service en différents groupes suivant leur utilisation. On isolera certains services, en fonction de leur priorité ou de leur fréquence d’utilisation par exemple, afin que si l’un d’entre eux tombe en panne en raison d’une trop forte demande, cela n’influe pas sur les autres.
Retry
Il arrive très souvent qu’un service soit temporairement indisponible, en raison par exemple de coupures réseau transitoires, d’une surcharge ponctuelle ou d’une corruption de paquets. Le pattern Retry peut être sollicité dans ce cas afin d’assurer la poursuite d’une opération de manière transparente. Suite à un premier échec, l’opération est à nouveau exécutée un certain nombre de fois après un délai (pouvant être incrémenté à chaque tentative), jusqu’à ce qu’elle soit réalisée ou que le nombre total d’essais soit atteint. La principale difficulté dans l’application de ce pattern réside dans le choix de valeurs correctes pour la durée du délai et le nombre de tentatives. Il n’y aura pas de risques à augmenter ce nombre dans le cas d’une opération indempotente [8]. On le réduira par contre tout en augmentant le délai de manière exponentielle dans les opérations de type batch.
Conclusion
Ces modèles de conception ne doivent pas nous faire oublier une caractéristique essentielle des microservices : le découplage. L’application de ces patterns doit être envisagée en fonction des besoins réels et n’aura pas d’effets concluants si les composants mis en œuvre n’ont pas été conçus dès l’origine de manière autonome. C’est en tout cas un bon moyen de mesurer l’efficacité et la pertinence de notre architecture.
[1] : La voie vers les applications natives pour le cloud. 2019 Red Hat
[2] : https://docs.microsoft.com/fr-fr/dotnet/architecture/microservices
[3] : https://medium.com/refraction-tech-everything/how-netflix-works-the-hugely-simplified-complex-stuff-that-happens-every-time-you-hit-play-3a40c9be254b
[4] : https://www.redhat.com/fr/topics/microservices/what-is-a-service-mesh
[5] : Cloud Ready Apps. https://www.octo.com/publications/cloud-ready-apps
[6] : Capacité à surmonter les défaillances
[7] : https://www.allthingsdistributed.com/2016/03/10-lessons-from-10-years-of-aws.html
[8] : Une opération retourne toujours les mêmes résultats quelque soit son nombre d’éxecutions. La méthode GET du protocole HTTP en est un exemple.